
Ship generative AI apps to production
with confidence.
Take your prototypes to production using the LastMile developer platform. We make it easy to debug & evaluate RAG pipelines, version & optimize prompts, and manage models.
Teaming up with companies like:



Workbench
Debug, Evaluate, and Optimize RAG systems with Workbench
Upgrade your RAG application with WorkbenchBeta. WorkbenchBeta provides you with personalized evaluation models, regression testing, debugging, and much more. Accelerate your time to production, while improving the quality of your RAG applications.
Auto-Eval
Detect hallucinations with small, targeted evaluator models
Faithfulness evaluators that outperform GPT-4 and run at 1/1000th the cost. Best of all, they can be fine-tuned for other RAG evals, like answer relevance, and customized with your application data (you own the model).
AIConfig
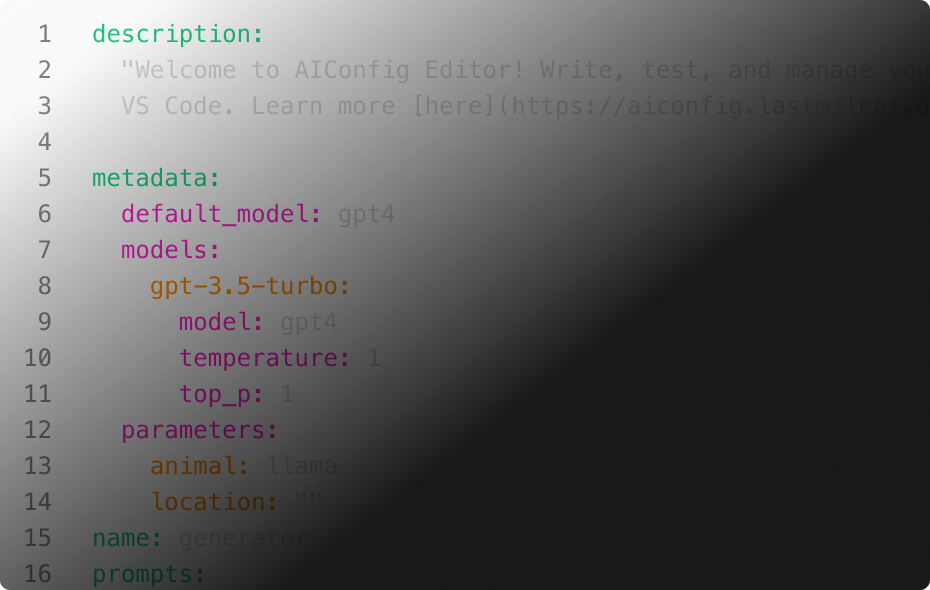
Version control and optimize prompts with AIConfig
Version, evaluate & optimize prompts and model parameters with an open-source framework that manages prompts as YAML configs.
Use AIConfig SDK to decouple model-specific logic from your application code and swap model providers with ease. Use AIConfig Editor as a universal prompt playground to optimize prompts for
any model or modality, including text, image and audio.
Service Mesh

Unified API for Accessing Third-Party Models
Unified API gateway that handle model inference, routing, response caching, monitoring and rate limiting.
Provision AI Service Mesh within your organization cloud to provide streamlined access to generative AI with admin controls and safety guardrails. Manage approved models, track costs, monitor usage, enforce rate limits and more.